
Data Platform enables open access to the data collected in ARPA

A marine vessel needs to form situational awareness of itself and its surrounding environment to be able to operate autonomously.
The situational awareness can be created using sensor fusion methods with data gathered from a multitude of different sensors [1]. The vessel’s AI algorithms can then make the needed navigational decisions based on the obtained situational awareness.
If we collect the data that the AI uses in the decision-making to a data platform, we can use the collected sensor data for example to virtually duplicate the exact environment and scenario of the vessel to a so-called digital twin. Digital twin is a virtual representation of physical object and its environment. In the virtual environment of the digital twin, we can for example modify the algorithms used to obtain the situational awareness from the sensor data or the decision-making algorithms for navigation and optimize the algorithms virtually before deploying them in real-world scenarios. Thus, this gives us a safe and fast method to develop the decision-making algorithms of our autonomous vessel. In this sense, data can be seen as the driving force behind AI research.
The lack of open datasets of multimodal sensor data from marine vessels makes developing AI models both difficult and costly [2]. Therefore, in ARPA project, we are developing a data platform for storing and publishing open datasets of maritime sensor data. Figure 1 shows the connection and dependencies of the data platform to the other aspects of ARPA project.
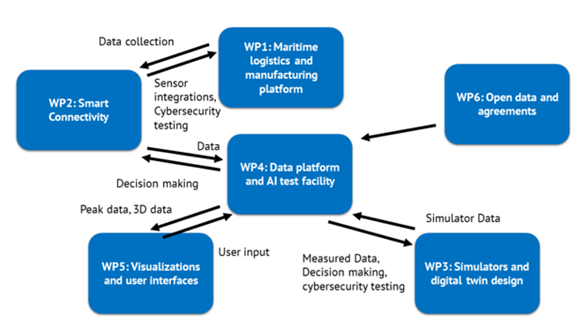
Figure 1. Connection and dependencies of the data platform to the other aspects of ARPA project.
How to develop a Data Platform?
The requirements for the data platform in ARPA project are two-fold. We need to both store the data from the ARPA sensor platform and to enable acquiring that data for use in visualization and AI research. There are several factors that need to be considered. We will discuss a few of the most interesting ones here concentrating on the data storages.
As discussed in the previous blog post ”Collecting Sensor Fusion Data for Autonomous Systems Research” [1], the autonomous systems are dependent on multiple different types of sensors. These sensors produce several types of data ranging from strings and key-value pairs to video frames, to name a few. This data needs to be stored in such a way that we can query the storage for a subset of data that we need at a given time and location.
Because of the multimodal nature of the data that we need to store and the fact that we may not yet even be aware of all the different media types the data may come in, we decided to consider all data as general data objects in ARPA data platform. After researching different available object storages and testing a select few, we ended up choosing LinkedIn’s Ambry for this purpose. Figure 2 illustrates a simplified diagram of the dataflow in the ARPA data platform implemented with Ambry.
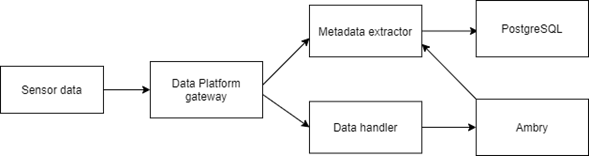
Figure 2. Simplified diagram of the dataflow. Ambry generates a unique identifier for each data object that is stored in the metadata in PostgreSQL.
Ambry is a highly scalable Java-based system consisting of a REST frontend and a NIO (non-blocking i/o) backend. It provides excellent performance for storing and immutable data, is open source, and it is being actively developed by a large enough company so that there’s a minimal risk of the development ending suddenly. LinkedIn uses Ambry to store their media files.
An object storage by itself would not be sufficient. To make querying the data decently performant, we store the metadata describing the objects stored in Ambry in PostgreSQL. PostgreSQL extended with PostGIS can be used to efficiently search the data filtering by location and time. Naturally, there were other possible SQL-based database systems available. Choosing PostgreSQL was trivial considering its formidable performance in situations demanding concurrent performance, excellent security options, and finally the positive experiences with PostgreSQL in previous large-scale projects.
Having separate database systems also provides us with an effective way to decouple the data objects from the metadata describing them. Standardized metadata is important for future co-operation with other data platforms. In addition to location and timestamps, we can store information about the used sensor, data ownership, and licensing. All of these are extremely important for data exchange.
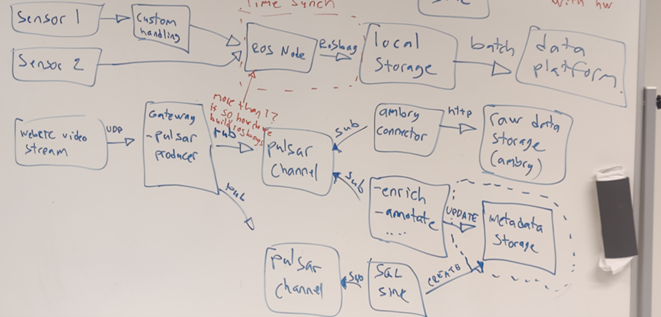
Figure 3. Design concepts of two different use cases for the data platform at different granularities: batch of data in RoSbag and a webRTC video stream.
Students participate in the development of the data platform
The data platform follows a microservices architecture. The main idea of this software architecture is that the application consists of a collection of independent services, each with their own responsibilities. The separate services do not need to be even written in the same programming language if they can communicate with each other over a common channel. This approach enables our students to participate in the development of the data platform.
A group of five students have been working with the data platform as part of their internship. They have been developing microservices which collect data, transfer it over Apache Pulsar, and store it in the data storages. Design concepts for different for storing different types of data are illustrated in Figure 3. Figure 4 illustrates a conceptualization of the students’ work with the data platform.
The ARPA project provides the students with experience with real life software development challenges, which are too large for regular programming courses. Their work has been invaluable in the development of the ARPA data platform.
Figure 4. Interns hard at work with the concepts and data flow within the data platform.
Tommi Tuomola, Software Developer, Turku University of Applied Sciences
Juha Kalliovaara, Senior Researcher, Turku University of Applied Sciences
References
[1] J. Kalliovaara, Collecting Sensor Fusion Data for Autonomous Systems Research, https://arpa-project.turkuamk.fi/yleinen/collecting-sensor-fusion-data-for-autonomous-systems-research/
[2] B. Iancu, V. Soloviev, L. Zelioli, J. Lilius, ABOships – An Inshore and Offshore Maritime Vessel Detection Dataset with Precise Annotations. Remote Sens. 2021, 13, 988. https://doi.org/10.3390/rs13050988